
Selected Research Projects
Representation Learning in Multi-granularity Linguistic Units for Word Segmentation
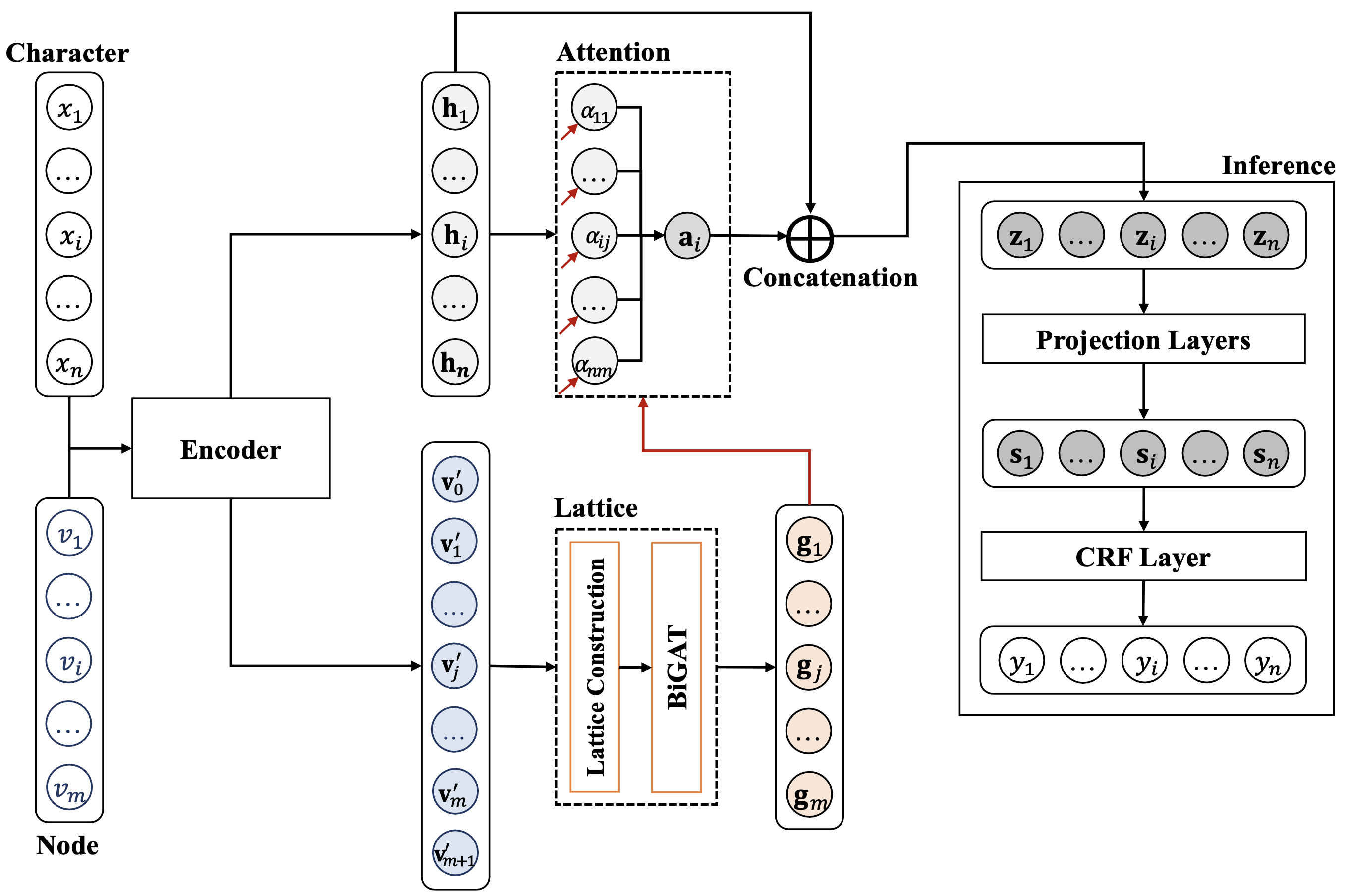
A character sequence tends to comprise segmentation alternatives, leading to segmentation ambiguity. Properly handling this ambiguity using multi-granularity linguistic units, such as character clusters, subwords, and words, can improve word segmentation performance and lessen ambiguous boundary decisions. We conduct a study to investigate the potential of using various linguistic units and leveraging segmentation alternatives for character-based word segmentation. Our experimental results demonstrated improvements in segmentation performance, outperforming previous work on the BCCWJ, CTB6, and BEST2010 datasets in Japanese, Chinese, and Thai, respectively.
Further reading:
- LATTE: Lattice ATTentive Encoding for Character-based Word Segmentation
- Character-based Thai Word Segmentation with Multiple Attentions
- Paperwithcode (SOTA): Chinese, Japanese, Thai
- Pre-trained models (Hugging Face): Chinese, Japanese, Thai
The First Treebank Construction for Thai Language
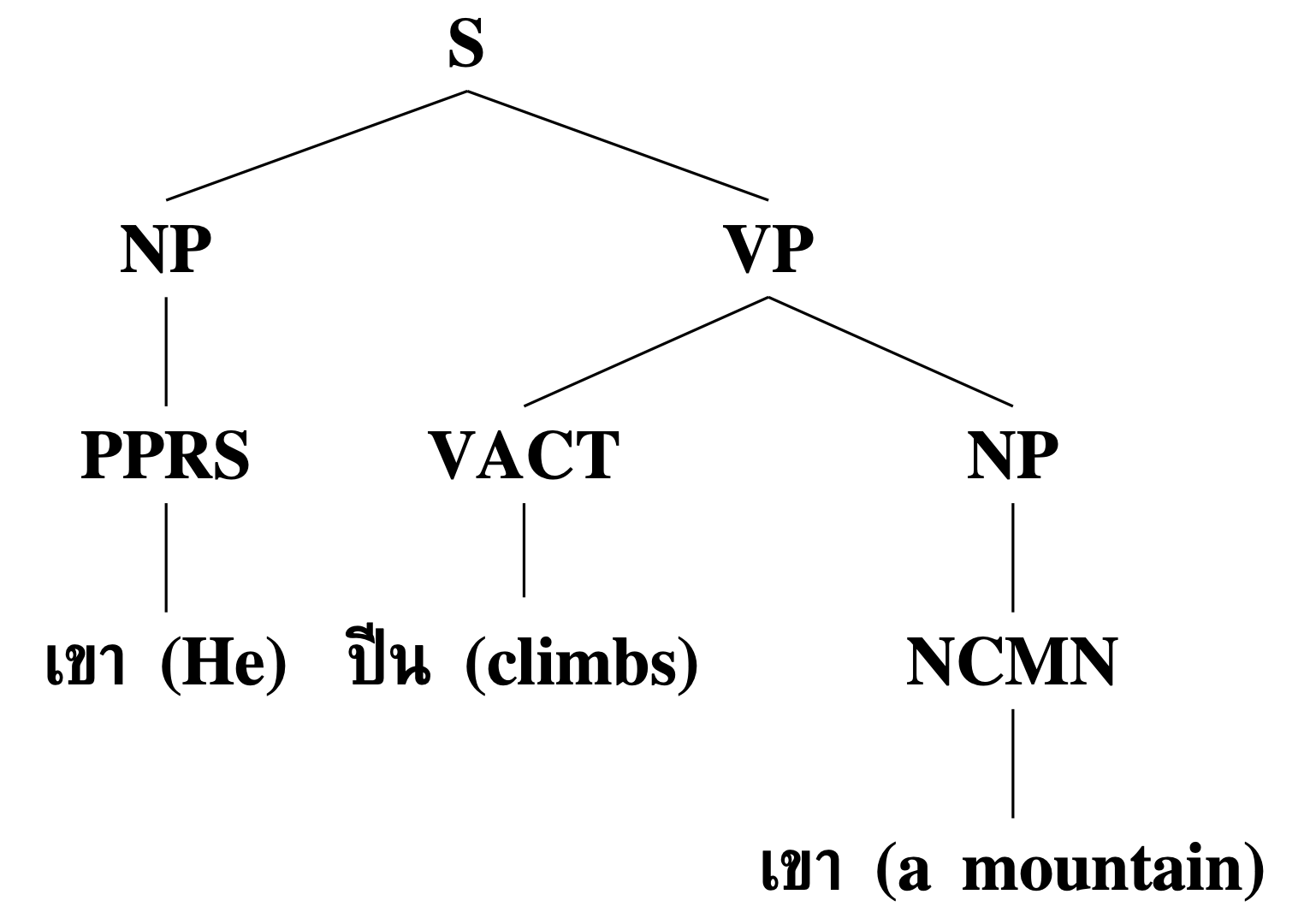
In this project, we address the scarcity of high-level syntactic resources for the Thai language, such as treebanks and grammars. We propose a framework for Thai treebank construction, including an annotation standard and a semi-automatic, iterative process for treebank development and threshold-based grammar refinement. Our approach begins with exploiting diverse textual genres to establish a gold standard treebank of training syntactic trees. Probabilistic grammar rules, extracted from this treebank, are iteratively refined using a probabilistic parser, enhancing the consistency and precision of both the treebank and grammars. Evaluation across three datasets (political commentaries, technical papers, and medical information) demonstrated improvements in parsing accuracy, parsable ratio, and ambiguity reduction. The process also facilitates the creation of a large-scale treebank by automatically parsing unseen sentences using refined grammars. Additionally, we developed CF Planter, an integrated toolset, to streamline the semi-automatic Thai treebank annotation process.
Further reading:
- A Framework of Thai Treebank Construction and Grammar Refinement
- CF Planter: A Toolset for Semi-automatic Thai Treebank Construction
- Try our CF Planter here.
- Click here to visit our repository.